
The memory wall and its implications
For decades, it has been recognized that advancements in memory performance are lagging processor performance. With the growing demand for increasingly complex AI models, this needs to be addressed.
As generative AI applications such as OpenAI’s ChatGPT and Sora become increasingly prevalent in today’s digital landscape, the demand for cutting-edge semiconductors has surged. Nvidia, with its dominant and near-monopoly position in the GPU (Graphics Processing Unit) market, has particularly captured the attention of investors since its GPUs are currently powering most new AI applications.
Yet, a critical challenge remains underexplored and unsolved: the “Memory Wall”. With each new and more complex AI model (increasing amount of parameters), the memory wall and lack of bandwidth becomes a growing limitation, which poses significant implications for the efficiency and scalability of AI technologies.
In fact, bandwidth is quickly becoming a limiting factor at many levels, not only for memory. For example at the network level, at the socket level, and at the compute level.
The Memory Wall
In essence, the memory wall refers to physical barriers that are limiting how fast data can be moved between a system’s memory and processor. For several decades, the semiconductor industry has noted that while processor performance has seen rapid improvements, advancements in memory speed have not kept pace. As displayed in the chart below, the performance gap continues to widen.
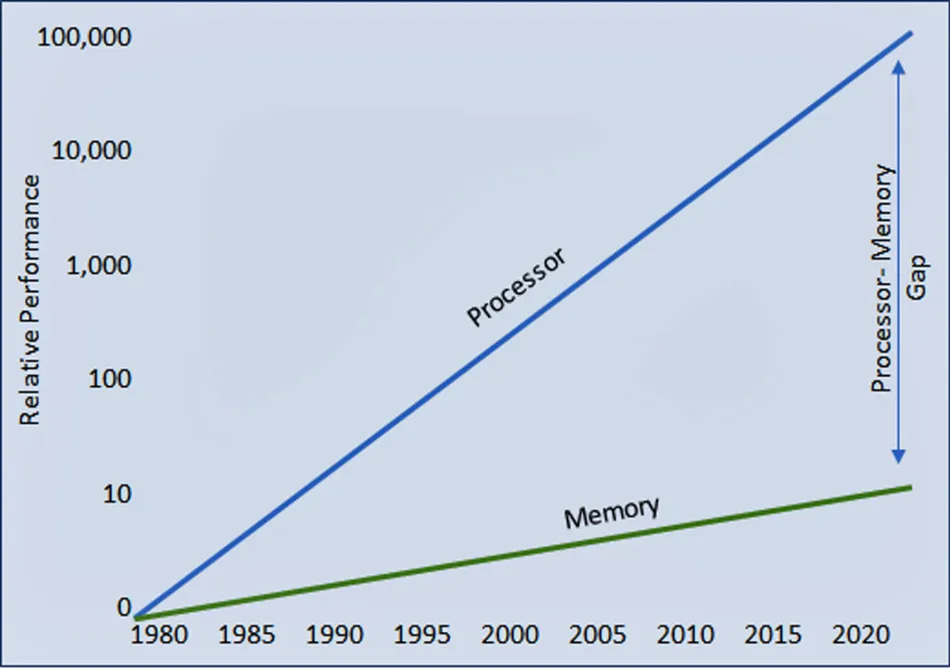
The performance gap created by the memory wall leads to a situation where CPUs and GPUs spend a significant amount of time waiting (idling) for data to be delivered from the memory, rather than doing actual processing work/computations. This significantly impacts overall system performance, especially for tasks that require large amounts of data to be processed quickly, such as running complex AI algorithms. To address this bottleneck, various strategies like enhancing memory speed, increasing cache sizes, and improving data retrieval techniques have been employed, but the challenge of the memory wall persists. And it is getting increasingly expensive to circumvent.
As you probably already have understood, the memory wall is quickly becoming a large issue for AI applications since Nvidia’s GPUs are specifically designed for efficient high-speed parallel processing of large amounts of data.
Below is an additional visualization, which shows the bandwidth scaling of different generations of memory (green) and interconnects (blue), versus CPUs/GPUs (black).

The practical implication of this performance discrepancy is that bandwidth for data transfer between memory and the processor, coupled with power usage, severely compromises processor efficiency. Without knowing exact figures, these bottlenecks cause expensive Nvidia H100 GPUs to become underutilized, highlighting a critical inefficiency in running various AI algorithms and models on them.
Furthermore, studies show that every time data is transferred across the memory bus, accessing DRAM requires approximately 60 picojoules for each byte, in contrast to 50-60 femtojoules needed per computational operation. Transporting data back and forth therefore requires a thousandfold more energy than processing it, leading to even larger ineffiencies.
How will the industry address this?
The current and expensive solution is called HBM (High-Bandwidth Memory). Compared to traditional DRAM, HBM consists of several memory dies that have been stacked on top of each other and connected through silicon. HBM allows for much higher bandwidth compared to traditional DRAM designs, by providing a wider interface at a higher clock speed.
Each Nvidia H100 GPU is packed with closely located 80GB of HBM3. Due to signal integrity reasons, the HBM needs to be placed within just a few millimeters from the actual GPU.
In theory, Nvidia’s GPUs could be packed with even more than 80GB. But today’s HBM is at least 4 times more expensive per GB than GDDR, and even more expensive compared to traditional DRAM. This is mainly due to the need for 3D packaging and the fact that HBM die size is roughly twice as large as that of traditional DDR5 DRAM. Additionally, the space available for HBM is limited because it must be placed very close to the GPU, in the area often referred to as the “beachfront”.
And despite that HBM enables faster data transfer, today’s interconnect between memory chips and the GPU is still holding back performance scaling. To speed up data transfer rates in the future, the industry needs to come up with better and more cost efficient solutions.
Regardless of all above, memory is currently forecasted to exceed 40% of the total server value by 2025.
CXL a potential, but not certain, future AI solution
A promising solution that potentially (I write potentially because there are limiting factors) could help mitigate the memory wall is the Compute Express Link (CXL) standard protocol. CXL is a high-speed CPU-to-device and CPU-to-memory interconnect protocol that supports more efficient use of both memory and accelerators such as GPUs. It is expected to enhance cache coherency, resource disaggregation and overall composability in data centers. Nvidia, Intel and AMD have joined the standard, together with all major DRAM manufacturers (SK Hynix, Samsung and Micron Technology).
In short, CXL could significantly reduce system latency by expanding server memory capacity up to tens of terabytes, and by boosting bandwidth to several terabytes per second. It achieves these improvements by facilitating access to larger memory pools with both lower latency and higher bandwidth, thus effectively bridging the gap between processing speeds and the slower speed of memory access.

However, CXL is currently in its early stages of deployment and is yet to see any large-scale adoption. Thus far it has seen little-to-none adoption, particularly within the AI space. Despite having joined the standard, Nvidia has not released a GPU with CXL support yet. AMD however, has recently released their MI300A GPU that supports CXL 2.0 and enables the implementation of memory pools.
But as mentioned in the previous section on HBM, the need for HBM to be closely located to the GPU could mean that CXL will struggle to make it into mainstream AI solutions, at least in the near term. Simply because there is a limited amount of space on the “beachfront” around the actual GPU. Nvidia is currently using parts of this space for NVLink, which is their own direct GPU-to-GPU interconnect solution.
Optical I/O and optical compute
In addition to the CXL standard protocol, innovative firms such as Celestial AI, Ayar Labs and Lightmatter are all working on various photonic/optical-based technologies that could increase bandwidth within and/or between different types of server components even further.
Celestial AI specifically targets compute-to-memory optical I/O (input/output) links by enabling optically connected HBM (O-HBM). If their Photonic Fabric solution is implemented correctly, it can eventually pool memory between multiple accelerators to increase utilization rates (of both HBM and processors) and lower server costs. As you probably have figured out already, their optical solution also supports the CXL protocol.
If you remember what I wrote about HBM requiring a lot of beachfront space around the actual GPU, which could be a limiting factor for CXL adoption within the AI space. Celestial AI’s Photonic Fabric is the only optical I/O platform that can deliver data at any point on the die, not restricted by the package beachfront. This allows Photonic Fabric to deliver not only an order of magnitude more bandwidth with significantly lower power and latency. It also does not compete with beachfront space around the GPU, which instead could be used for more HBM. My guess is that this technology, if adopted, also could lead to HBM being located off the main chip, and still being able to deliver significantly increased bandwidth at lower latency.
“Photonic Fabric can deliver data at any point on the silicon, directly at the point of compute. It is unrestricted by the silicon beachfront and thus can offer direct fully optical compute-to-memory links. This allows the processor to address optically connected HBMs (O-HBMs) in addition to the conventional electrical HBMs along the die edge.” - Celestial AI
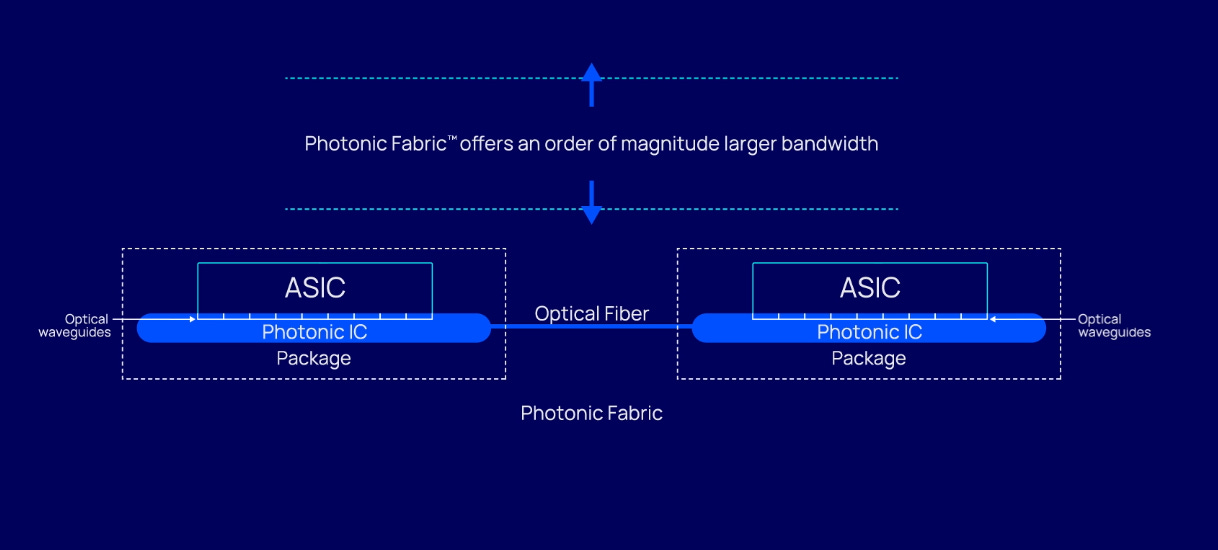
Celestial AI asserts that their optical solution delivers 25x the bandwidth, and 10x lower latency and power consumption compared to any other optical interconnect alternative (such as co-packaged optics/CPO). The company raised $100 million in a Series-B round last year.
Lightmatter is another company that explores photonics-based solutions. Their solutions are called Passage and Envise. Passage is a silicon photonics interposer which has been designed to support high speed chip-to-chip and node-to-node optical I/O. An interposer is essentially a bridge that allows components that wouldn't normally fit together to be connected and communicate with each other.
If for example HBM and a processor gets attached to the surface of a Passage tile, data will move electrically between the chips on that specific tile, but optically across tiles. The results will be significantly increased bandwidth.

The company’s most interesting product however, is Envise. It is an optical compute solution, a general-purpose machine learning accelerator that integrates photonics with traditional transistor-based systems. Envise integrates photonic and electronic components on a single chip, which in turn will enable more efficient computation by using light. If coupled with their Passage solution, or any other optical I/O solution, this type of technology will enable a giant leap for AI and machine learning performance.

In December last year, Lightmatter raised $155 million in a second Series-C round. In total, the company has raised $420 million to-date.
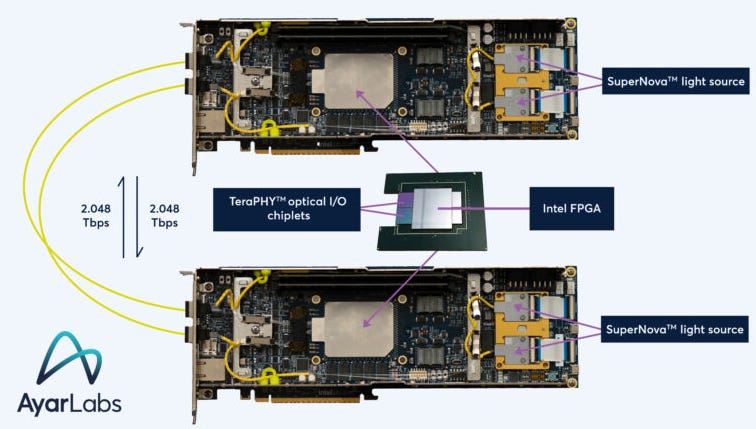
Ayar Labs is another industry unicorn, funded by Intel, Nvidia and HPE among others. Their flagship product, the TeraPHY, is a chiplet that leverages optical I/O technology to facilitate communication between chips at significantly lower power consumption compared to traditional electrical I/O technologies. TeraPHY is designed to replace copper-based connections, offering up to 100x higher bandwidth density and a considerable reduction in power consumption and latency. It also supports the new CXL standard.

In addition to its TeraPHY, Ayar Labs has also developed the SuperNova light source, an external laser source that powers their TeraPHY chiplets, ensuring high performance and reliability for optical data transmission.
Together, TeraPHY chiplets and the SuperNova light source can provide a range of configuration options. They can, for example, be combined on a single printed circuit board. It is also possible to integrate multiple TeraPHY chiplets within one package with for example an FPGA. Below is a visualization of Ayar Labs’ solution in an Intel Agilex FPGA.

What companies could benefit in the near term?
First and foremost, Nvidia is the clear near-term beneficiary. As long as Nvidia’s own solutions (for example NVLink) enable them to offer superior performance over competitors, they will most likely not include CXL or other standard protocols.
The second most prominent and near-term beneficiaries are HBM3/3E manufacturers. HBM3/3E manufacturers include SK Hynix (000660.KS), Micron Technology (MU) and Samsung (005930.KS). Among these three, SK Hynix has been, and still is, the market leader. However, in H2 2024 Micron will start shipping their 24 GB 8H HBM3E for Nvidia’s upcoming H200 AI accelerator, thus chewing some of SK Hynix’s market share. Until we see any large-scale CXL and/or various photonics deployments, I believe that the demand for HBM will continue to grow at a high rate.

A positive sidenote to the ongoing HBM3/3E volume ramp is that the die size of these HBM chips is approximately twice as large as standard DDR5 DRAM. As a result, HBM3/3E demand will most likely absorb quite a substantial portion of the industry’s wafer supply, thus reducing overall DRAM bit supply growth going forward. It could potentially lead to rising DRAM ASPs (average selling prices) further into this market cycle. Especially considering how conservative these companies’ capex spend has been in recent years. It could potentially lead to a very beneficial market environment for memory suppliers.
Companies that are directly involved in supporting the development and adoption of CXL include for example Rambus (RMBS), Marvell Technology (MRVL), Microchip Technology (MCHP) and Astera Labs (soon to IPO).
If turning to the optical solution, I have already mentioned Ayar Labs, Lightmatter and Celestial AI as a few examples. However, all three of them are private companies.
In the public space, I would have a look at companies that are providing the light sources (the laser arrays) for these three companies. Sivers Semiconductors (SIVE.ST) has been working closely with Ayar Labs for several years now (I also suspect that Sivers is working with Lightmatter and Celestial AI, but it has not been confirmed yet). Ayar Labs is also working with Macom (MTSI) and Lumentum (LITE).

Also, I would be surprised if either Broadcom (AVGO) or Coherent (COHR) does not enter this market soon. It is already rumored that Broadcom is working with Nvidia and TSMC on some sort of silicon photonics solution.
Then we of course have all the manufacturing equipment suppliers that will enable these optical solutions to become reality. But it is a topic for another article.